It’s a common situation when making a website with forms – you want to make sure the user gives you information and you want to make sure the information is valid. At the same time you want to limit users from putting in harmful information. Should be an easy task, right? After all, everyone has filled out an online form by this point, and there are literally thousands of forms out there on the Web that you can reference. Different types of data are rigidly defined. Some of them by governing bodies no less, so there’s documentation out there you can reference to get the exact format of data to be entered. Am I saying form validation is difficult?
It can be. Let’s look at an example. ZIP codes are a common thing. They’re rigidly defined by a governing body (the United States government), and everyone writes them the same way. It’s a number, so let’s give the user a field to enter a number into. With that information in mind, we can safely make an input field that takes in numbers, right?
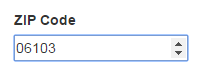
Wrong. A ZIP code is not necessarily a number. It is a string of digits, but take one of Hartford, Connecticut’s ZIP codes. It starts with a zero – meaning if you feed that value to your back-end, or even to some JavaScript expecting an integer, you’re going to get some strange results, if not errors outright. To make things worse, if the user does write the full ZIP+4 with a hyphen, JavaScript does not correctly access the value of the field but instead gets an empty string (tested in Chrome 49.0, could change between versions). Your HTML should not be an input with a “number” type. It should be “text”. Mobile browsing is big and all of your mobile users are going to see a number pad when they set their focus on this field. What if they want to enter 9 digits for a ZIP+4 code? The separating hyphen involved is not valid for a number field and is not always available on a mobile number pad, rendering it impossible for the average user to enter and frustratingly difficult for someone more savvy.
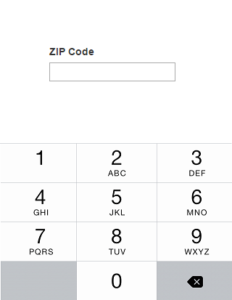
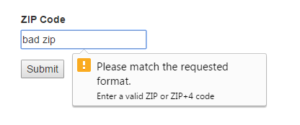
Okay, so maybe not being able to enter the optional +4 code isn’t the worst user experience you can have. At this point we know a ZIP code is a string, mostly digits, and there should be 5 or 9 digits in that string. If you want to keep a user within those limits, there’s an underutilized HTML5 attribute for something like this, the pattern attribute. It allows you to put in a regular expression that must be matched when a form element is submitted. It’s currently supported by Firefox, Chrome, Opera, and some of the mobile browsers, so it doesn’t have full support it’s another nice tool in your web design belt and complements the required attribute. Of course, you want to validate the data server-side too.
We have one final consideration here, just who are our users? Are they all American? A few Canadians in there? Well, if we’re adding Canada to the mix, then we can no longer call them ZIP codes, they need to be generalized to “postal codes”. Oh, and our pattern is no longer valid. Canadian postal codes are alphanumeric: 3 characters, a space, and 3 characters (XXX XXX). So you re-write your validations, because you’re getting emails from potential customers in Toronto that couldn’t get submit orders through your bad form. You’re now confident that someone could put in a shipping address to all US states and territories and all Canadian provinces and territories. That is assuming your State/Province/Territory/Capital District select field includes all of these places as options. Can we add some other nations into the fold? Sure, but it’s going to take some re-work. Now our “postal code” field is doing quite a lot of work. Postal codes around the world range in length from 3 to 10 alphanumeric characters with different kinds of separators in-between. Furthermore, they’re no longer required. Several countries do not use postal codes at all.
At this point you may be convinced that the simplest form of validation is just to make sure the user entered data and that that data isn’t too long. Which brings us to names. There is already a great post about names and the common misconceptions programmers make about them, but I feel it’s still worth talking about if only to realize how futile input validation can be. Most systems would expect a person’s name to be a requirement: there has to be something entered in there. But what is a name? It’s not necessarily composed of two parts (first and last), there’s no guarantees that any part of that name won’t have white space or punctuation included within it, and names most definitely aren’t limited to the ASCII character set or even Latin characters. So with just those few considerations in mind it becomes unrealistic to try to put strict limits on a person’s name. But there must be some, technology, specifically databases, demand it of us. A name must conform to the character encoding of the database it will eventually reside in. I’m willing to bet that for most databases that means Latin characters only, Latin extended if you’re lucky. Most SQL databases have a hard limit to the length a string field can be (usually to the tune of 255 characters). Additional to that consideration is the security concern that it’s much easier to protect against SQL injection if the input size is smaller. Practicality comes into play when it comes time to accept user’s names as input. One of the worst things you could do with the input is run it through an automatic language checker that blocks Mr. Cummings or Mr. Cock because their surnames were flagged for foul language. I think taking a look at passport standards and what they allow for names is a good rule of thumb for determining this sort of thing since a passport is perhaps one of the most official documents out there.
So do the Von Neumanns, the Lis, the Mary-Kates, the ![]() s, the D’Artagnans, the Cocks, and the Pablo Diego José Francisco de Paula Juan Nepomuceno María de los Remedios Cipriano de la Santísima Trinidad Ruiz y Picassos of the world a favor and don’t make the name field too restrictive.
s, the D’Artagnans, the Cocks, and the Pablo Diego José Francisco de Paula Juan Nepomuceno María de los Remedios Cipriano de la Santísima Trinidad Ruiz y Picassos of the world a favor and don’t make the name field too restrictive.